网站做大了就不免各自采集和爬虫以及垃圾评论找上门,我最近一个网站就遭遇到了采集,还换着IP和UA来采,爬虫太多,把服务器都拉垮了。不得不研究一种防爬虫的方法。
reCAPTCHA v3这种无感知验证码正好用于防止爬虫机器人。在这篇文章中,我将展示在站点上集成reCAPTCHA v3的代码示例,以防止使用机器人浏览页面,防止站点上的自动操作,并阻止垃圾评论。
Google官方站点的reCAPTCHA v3说明文档相当糟糕,而且令人困惑。我将逐步展示一个向站点添加reCAPTCHA v3的示例,并解释使用代码(PHP和JavaScript),以便您可以进行必要的更改。
由于我也将reCAPTCHA v3集成到一个已经运行的项目中,并提供了大量的源代码,所以我为自己选择了对网站现有代码进行最小干预的方法。例如,当添加了reCAPTCHA v3来验证表单发出的请求时,表单的源代码根本不会发生变化——将插入一小段JavaScript代码,这将向事件添加侦听器并动态地进行必要的更改。
谷歌reCAPTCHA v3不同于以前的版本reCAPTCHA v2,在这一点上完全不需要用户做任何操作。也就是说,验证会自动且不受察觉地通过。由于这种方法,除了通常集成到表单(用于发送评论、反馈、访问服务)之外,reCAPTCHA v3还可以用来保护浏览页面免受机器人的攻击。
原理如下:
用户请求一个页面,但在响应之前,执行一个检查该用户是否是机器人。如果用户不是人类,那么我们禁止显示页面。
原则上,这个选项可以用reCAPTCHA v2实现,但您可以确定,当有人看到验证码以访问页面时(即使他们只需要点击一次鼠标),许多用户只是简单地关闭浏览器选项卡。谷歌reCAPTCHA v3就没有这个缺点,因为用户不会看到任何东西,也不需要从他那里采取任何行动。
阻止机器人访问网站有什么影响?
虽然下面描述的用于访问所有机器人网站的阻塞技术有效地帮助防止网站内容被爬取,而正常用户是完全看不到的,完全阻塞机器人有非常重要的后果。因此,请考虑在阻止访问bots网站时需要注意一些事项。
首先,所描述的技术不仅可以阻止坏的机器人,也可以阻止好的机器人——比如谷歌这样的搜索引擎。这将导致一个事实,如果没有采取额外的措施(例如,允许访问一个属于谷歌的IP绕过验证码的网站),那么这个网站将从搜索引擎的索引中掉出来。
其次,一些联盟程序不允许广告显示在被拒绝访问的页面上(如medipartners -Google和AdsBot-Google* for谷歌AdSense)。如果广告显示在受保护的站点上,那么您需要提供绕过验证码的页面访问——因为这些机器人本身无法通过“人类测试”。
与此同时,为了绕过验证码而对机器人进行访问的质量检查在任何情况下都不应该仅仅基于客户端用户UA,因为它很容易被欺骗。
我们可以采用rDNS来判断是否只正常蜘蛛bot, 从而放行好的蜘蛛bots.
对于阻止爬虫bot访问,本文考虑了两种阻止方法:
- 阻止以查看该网站
- 阻止表单提交
你可以选择最适合你的。或者,将这两种技术结合起来:例如,为授权页面配置完全阻塞访问,为反馈页面、评论表单等配置定期阻塞访问。
哪里可以得到谷歌reCAPTCHA v3密钥
使用reCAPTCHA v3是免费的。您只需要指定域并选择reCAPTCHA v3或v2。在本文中,我将考虑使用V3版本。
要获得钥匙,请点击链接:https://www.google.com/recaptcha/admin/create
 随后,您可以从https://www.google.com/recaptcha/admin查看统计数据并访问设置。
随后,您可以从https://www.google.com/recaptcha/admin查看统计数据并访问设置。
reCAPTCHA v3如何工作
用户评价(bot或person)的初始阶段完全由JavaScript进行。也就是说,没有JavaScript支持的机器人在这个阶段已经被淘汰了。顺便说一句,显然,这些机器人也不属于请求统计。
在其工作过程中,reCAPTCHA v3收集与站点交互的数据,并形成一个长字符串——令牌(token)。
此令牌(token)需要传输到为站点提供服务的服务器,并且已经使用密钥的服务器必须向reCAPTCHA v3服务发出请求。答案在本质上是概率性的——一个从0(机器人)到1(人)的数字将被发送。您需要自己决定这个站点的阈值是多少。
根据这些信息,服务器必须决定是否处理从用户接收到的请求(例如,是否向他显示页面,是否接受从表单发送的数据,等等)。
启用v3版本的reCAPTCHA
我的实现由两段PHP代码组成。第一个文件最好放在文件的开头。应该定位第二个片段,以便它的HTML输出位于站点源代码的末尾。您不需要在PHP中专门这样做——您可以用不同的方式插入这个片段——只是在这种情况下,注意单引号被转义了——不要忘记取消转义(删除反斜杠)。
在显示代码(我还在其中添加了许多注释)之前,我将首先解释它是如何工作的。在最开始的时候,检查用户是否有令牌(token)。如果没有,则不会向用户显示站点页面,而是输出HTML/JavaScript代码,它只接收令牌,并立即将用户返回到索引页面(保存所有GET请求,并向它们添加另一个变量,它是令牌)。
然后再次检查用户是否拥有令牌,如果它已经存在,则向reCAPTCHA v3服务发出请求。如果答案是肯定的(这是一个人),那么代码结束它的工作-控制转移到站点的主代码。如果答案是否定的(这是一个机器人),那么代码将终止此请求的后续处理——也就是说,它将立即停止工作,并且不将控制权转移到主站点代码。
第一部分代码负责在访问站点时检查机器人,在发送表单时检查机器人。
第一个片段代码
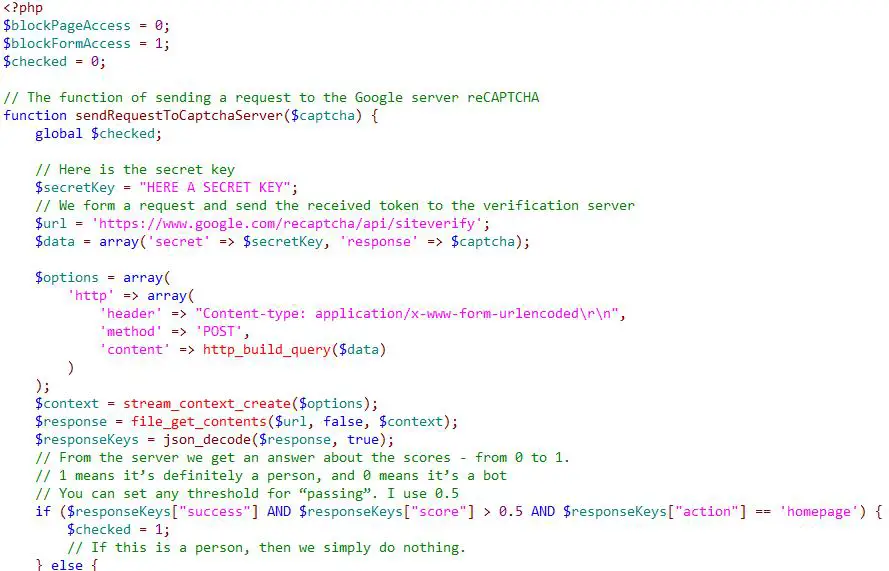
注意变量:
$blockPageAccess = 0;$blockFormAccess = 1;
第一种允许在访问页面时进行检查(默认禁用),第二种允许在接受表单时进行检查。将这些值设置为您需要的配置(它们彼此独立工作)。
第二个片段: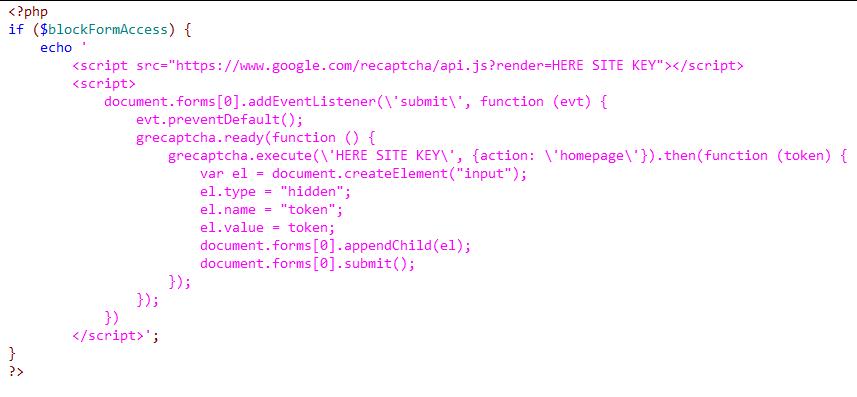
只有在提交表单时启用了bot检查时才需要此代码。这段代码的意思是,在每次表单提交之前都会向表单添加一个令牌。令牌本身是在表单发送时获得的——在点击“发送”按钮和发送本身之间没有额外的延迟。
这是没有jQuery的纯JavaScript。注意我是如何称呼表单的:
document.forms [0]
事实上,我有一个没有名称和标识符的表单。而且,网站的每个页面都有独特的形式,其中有一百多个。幸好每一页只有一个表单,所以我用它的订单号来指代它。您可以根据您的条件编辑它。
别忘了设置你自己的钥匙:
- 在第一个片段中,您需要设置一个私钥和两个站点的密钥(在输出的HTML/JavaScript代码中)
- 在第二个片段中,您只需要安装site key两次-它也将在面向用户的HTML/JavaScript代码中
官方谷歌文档reCAPTCHA v3
官方信息和说明可在以下页面找到:
就像官方文档经常出现的情况一样——在它的基础上,不可能理解任何东西,也不可能将任何东西配置为工作状态……
同时,该指令包含一个关键的逻辑错误——发送的成功字段用于做出决定。但事实是,这个字段仅指示发送的令牌是否是这个站点的正确令牌——无论机器人是否是机器人,这个字段都不指示。真正的指导价值是分数。过一会儿再说。也就是说,如果您在检查中使用success,那么即使显式机器人可能得分为0,但设法获得令牌,也将成功通过测试。
然而,官方文档中有一些关于reCAPTCHA的认知事实——让我们来考虑一下。
首先,它说来自reCAPTCHA服务的检查结果作为一个JSON对象返回。转换为数组后,它是这样的:
Array ( [success] => 1 [challenge_ts] => 2019-05-28T15:39:16Z [hostname] => suip.biz [score] => 0.9 [action] => homepage )
各字段的取值如下:
{ "success": true|false, // whether this request was a valid reCAPTCHA token for your site "score": number // the score for this request (0.0 - 1.0) "action": string // the action name for this request (important to verify) "challenge_ts": timestamp, // timestamp of the challenge load (ISO format yyyy-MM-dd'T'HH:mm:ssZZ) "hostname": string, // the hostname of the site where the reCAPTCHA was solved "error-codes": [...] // optional}
没有用户交互的reCAPTCHA v3为每个请求返回点。这些点是基于与你的网站的交互,并让你有机会根据它们做出决定。
令牌的限制
每个reCAPTCHA用户响应令牌的有效期为两分钟,并且只能验证一次(以防止重放攻击)。如果您需要一个新的令牌,那么重新启动reCAPTCHA验证。
在您收到响应令牌之后,您需要使用适当的api在两分钟内用reCAPTCHA验证它,以确保它是有效的。
在你网站上的位置
reCAPTCHA v3将永远不会中断您的用户,所以您可以随时运行它,没有负面影响。当reCAPTCHA在与你的站点的交互中有最多的上下文时,它会工作得更好,这有助于看到合法和不合法的用户。由于这些原因,建议在表单或动作上包括reCAPTCHA检查,以及在页面的背景中进行分析。
注意:您可以在同一页面上使用不同的操作多次执行reCAPTCHA。
reCAPTCHA v3返回分数(1.0很可能是良好的交互,0.0很可能是机器人)。基于这些分数,您可以在站点的上下文中采取各种行动。每个网站是不同的,但是下面是一些网站如何使用分数的例子。就像下面的例子,为了更好地保护你的网站,请遵循幕后的步骤,而不是阻塞流量。
| 用例 | 建议 |
|---|---|
| 主页 | 查看管理面板中的全貌:有多少用户来了,有多少各种类型的解析器 |
| 登录 | 如果分数较低,则要求双重身份验证或邮件验证,以防止与攻击相关的凭据 |
| 社会 | 向怀疑机器人的用户发送评论,限制他们向好友发送未回复请求的数量 |
| 电子商务 | 优先考虑真正的客户,找出可能不真实的要求 |
reCAPTCHA是通过观察你网站上真实的流量来训练的。因此,开发阶段和实现后的点可能与生产阶段不同。因为reCAPTCHA v3根本不会显示自己,所以您可以先运行reCAPTCHA而不采取任何行动,然后决定阈值,并在管理员控制台中分析获得的结果。默认情况下,您可以使用0.5的阈值。
结论
我为我的网站的特定特性编写了这段代码。同样的事情有可能做得更优雅。但它的主要优点是:
- 它的工作原理
- 你只需要插入这些片段-你不需要纠正已经存在的代码。甚至不需要为表单提供名称或标识符——如果没有的话
- 如果有必要,您可以通过将变量的值设置为零来禁用代码的工作——不需要执行更深层次的编辑
事实上,还有很多改进空间:例如,在上面的实现中,检查从用户接收到的每个请求。例如,在第一次检查之后,您可以将批准的IP地址保存在服务器上一段时间,并允许它在不进行检查的情况下被访问。或者,您可以生成一个惟一的令牌,并将其存储在用户的cookie和服务器上的数据库中,使这个令牌在10分钟内有效。
当安装一个完整的访问检查,你可以添加一个功能,检查IP由WHOIS,并让访问的网站没有captcha IP拥有的谷歌-这样搜索引擎蜘蛛可以继续访问网站。
通过改进上述代码,我加了个搜索引擎蜘蛛判断代码:
function detectSearchBot($ip, $agent, &$hostname){ $hostname = $ip; // check HTTP_USER_AGENT what not to touch gethostbyaddr in vain if (preg_match('/(?:google|yandex|baidu|bing|yahoo|sogou)bot/iu', $agent)) { // success - return host, fail - return ip or false $hostname = gethostbyaddr($ip); // https://support.google.com/webmasters/answer/80553 if ($hostname !== false && $hostname != $ip) { // detect google and yandex search bots if (preg_match('/\.((?:google(?:bot)?|bing|baidu|yahoo|sogou|yandex)\.(?:com|ru))$/iu', $hostname)) { // success - return ip, fail - return hostname $ip = gethostbyname($hostname); if ($ip != $hostname) { return true; } } } } return false;}
然后再加了了个设置cookie的代码,cookie 通过authcode函数来加密。
setcookie('_r', authcode($responseKeys['score'], time()+7200, '/','', 0);
最后如果验证不通过,给访客跳到验证码页面reCAPTCHA V2*。
经过几天的调试,最终代码工作正常,替换了上文中get方式传token,改用了post方式来传。这样不会改变网址导致Adsense广告不显示,详见《利用reCAPTCHA v3制作防火墙屏蔽爬虫采集》