做视频不想用自己的真声,那么可以采用ChatTTS最接近真实人声的文本转语音工具,用它吧文本转换成mp3语音后,再用PR等视频软件插入到视频中做配音。
Chat TTS是一款专为对话场景打造的文本转语音模型,适用于LLM助手对话等任务。该模型支持中英两种语言,并采用了超过10万小时中英文数据进行培训最终开发而成。HuggingFace上公开的版本则是经过4万小时训练、未进行SFT处理的版本。
特色亮点:
- 对话式优化: Chat TTS专门针对对话式任务进行优化,能够提供自然流畅的语音合成体验,并支持多种说话人角色。
- 细粒度调控: 该模型能够精准预测及调控语音的细节特征,如笑声、停顿和插入词等,使对话更加生动。
- 高级韵律表现: ChatTTS在韵律呈现上超越了多数开源TTS模型,同时还提供预训练模型,便于进行更深层次的研究与开发。
ChatTTS的应用场景
- 虚拟助手和客服机器人:ChatTTS可以为虚拟助手和在线客服机器人提供自然、流畅的语音输出,提升用户体验。
- 有声读物和电子书:将文本内容转换为语音,为有声书和电子书提供语音朗读功能,方便用户在通勤或做家务时收听。
- 社交媒体和内容创作:在社交媒体平台或内容创作中,ChatTTS可以生成吸引人的语音内容,增加互动性和趣味性。
- 新闻和播客:自动将新闻稿或博客文章转换成语音,用于播客或新闻广播。
- 无障碍辅助:为视障人士或有阅读困难的用户提供语音辅助,使他们能够通过听来获取信息。
ChatTTS webUI & API
https://github.com/jianchang512/ChatTTS-ui
一个简单的本地网页界面,在网页使用 ChatTTS 将文字合成为语音,支持中英文、数字混杂,并提供API接口。
原始ChatTTS项目: https://github.com/2noise/chattts
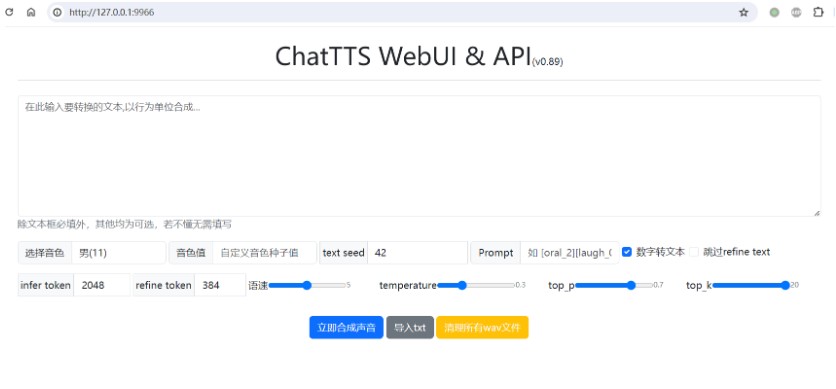
ChatTTS效果展示
试听合成语音效果
普通用户可以在ModelScope和Hugging Face上运行社区提供的在线ChatTTS WebUI版的Demo直接体验
ModelScope版Demo:
https://www.modelscope.cn/studios/AI-ModelScope/ChatTTS-demo/summary
Hugging Face版Demo:
https://huggingface.co/spaces/Dzkaka/ChatTTS
ChatTTS 一键本地安装
Windows预打包版下载地址:https://github.com/jianchang512/chatTTS-ui/releases
从 Releases中下载压缩包,解压后双击 app.exe 即可使用
某些安全软件可能报毒,请退出或使用源码部署
英伟达显卡大于4G显存,并安装了CUDA11.8+后,将启用GPU加速
Linux 下容器部署
安装
拉取项目仓库
在任意路径下克隆项目,例如:
git clone https://github.com/jianchang512/ChatTTS-ui.git chat-tts-ui
启动 Runner
进入到项目目录:
cd chat-tts-ui
启动容器并查看初始化日志:
gpu版本
docker compose -f docker-compose.gpu.yaml up -d
cpu版本
docker compose -f docker-compose.cpu.yaml up -d
docker compose logs -f –no-log-prefix
访问 ChatTTS WebUI
启动:[‘0.0.0.0’, ‘9966’],也即,访问部署设备的 IP:9966 即可,例如:
本机:http://127.0.0.1:9966
服务器: http://192.168.1.100:9966
更新
Get the latest code from the main branch:
git checkout main
git pull origin main
Go to the next step and update to the latest image:
docker compose down
gpu版本
docker compose -f docker-compose.gpu.yaml up -d –build
cpu版本
docker compose -f docker-compose.cpu.yaml up -d –build
docker compose logs -f –no-log-prefix
Linux 下源码部署
配置好 python3.9-3.11环境
创建空目录 /data/chattts 执行命令 cd /data/chattts && git clone https://github.com/jianchang512/chatTTS-ui .
创建虚拟环境 python3 -m venv venv
激活虚拟环境 source ./venv/bin/activate
安装依赖 pip3 install -r requirements.txt
如果不需要CUDA加速,执行
pip3 install torch==2.2.0 torchaudio==2.2.0
如果需要CUDA加速,执行
pip install torch==2.2.0 torchaudio==2.2.0 –index-url https://download.pytorch.org/whl/cu118
pip install nvidia-cublas-cu11 nvidia-cudnn-cu11
另需安装 CUDA11.8+ ToolKit,请自行搜索安装方法 或参考 https://juejin.cn/post/7318704408727519270
除CUDA外,也可以使用AMD GPU进行加速,这需要安装ROCm和PyTorch_ROCm版本。AMG GPU借助ROCm,在PyTorch开箱即用,无需额外修改代码。
请参考https://rocm.docs.amd.com/projects/install-on-linux/en/latest/tutorial/quick-start.html 来安装AMD GPU Driver及ROCm.
再通过https://pytorch.org/ 安装PyTorch_ROCm版本。
pip3 install torch==2.2.0 torchaudio==2.2.0 –index-url https://download.pytorch.org/whl/rocm6.0
安装完成后,可以通过rocm-smi命令来查看系统中的AMD GPU。也可以用以下Torch代码(query_gpu.py)来查询当前AMD GPU Device.
import torch
print(torch.__version__)
if torch.cuda.is_available():
device = torch.device(“cuda”) # a CUDA device object
print(‘Using GPU:’, torch.cuda.get_device_name(0))
else:
device = torch.device(“cpu”)
print(‘Using CPU’)
torch.cuda.get_device_properties(0)
使用以上代码,以AMD Radeon Pro W7900为例,查询设备如下。
$ python ~/query_gpu.py
2.4.0.dev20240401+rocm6.0
Using GPU: AMD Radeon PRO W7900
执行 python3 app.py 启动,将自动打开浏览器窗口,默认地址 http://127.0.0.1:9966 (注意:默认从 modelscope 魔塔下载模型,不可使用代理下载,请关闭代理)
MacOS 下源码部署
配置好 python3.9-3.11 环境,安装git ,执行命令 brew install libsndfile git python@3.10 继续执行
export PATH=”/usr/local/opt/python@3.10/bin:$PATH”
source ~/.bash_profile
source ~/.zshrc
创建空目录 /data/chattts 执行命令 cd /data/chattts && git clone https://github.com/jianchang512/chatTTS-ui .
创建虚拟环境 python3 -m venv venv
激活虚拟环境 source ./venv/bin/activate
安装依赖 pip3 install -r requirements.txt
安装torch pip3 install torch==2.2.0 torchaudio==2.2.0
执行 python3 app.py 启动,将自动打开浏览器窗口,默认地址 http://127.0.0.1:9966 (注意:默认从 modelscope 魔塔下载模型,不可使用代理下载,请关闭代理)
Windows源码部署
下载python3.9-3.11,安装时注意选中Add Python to environment variables
下载并安装git,https://github.com/git-for-windows/git/releases/download/v2.45.1.windows.1/Git-2.45.1-64-bit.exe
创建空文件夹 D:/chattts 并进入,地址栏输入 cmd回车,在弹出的cmd窗口中执行命令 git clone https://github.com/jianchang512/chatTTS-ui .
创建虚拟环境,执行命令 python -m venv venv
激活虚拟环境,执行 .\venv\scripts\activate
安装依赖,执行 pip install -r requirements.txt
如果不需要CUDA加速,
执行 pip install torch==2.2.0 torchaudio==2.2.0
如果需要CUDA加速,执行
pip install torch==2.2.0 torchaudio==2.2.0 –index-url https://download.pytorch.org/whl/cu118
另需安装 CUDA11.8+ ToolKit,请自行搜索安装方法或参考 https://juejin.cn/post/7318704408727519270
执行 python app.py 启动,将自动打开浏览器窗口,默认地址 http://127.0.0.1:9966 (注意:默认从 modelscope 魔塔下载模型,不可使用代理下载,请关闭代理)
部署注意
如果GPU显存低于4G,将强制使用CPU。
Windows或Linux下如果显存大于4G并且是英伟达显卡,但源码部署后仍使用CPU,可尝试先卸载torch再重装,卸载pip uninstall -y torch torchaudio , 重新安装cuda版torch。pip install torch==2.2.0 torchaudio==2.2.0 –index-url https://download.pytorch.org/whl/cu118 。必须已安装CUDA11.8+
默认检测 modelscope 是否可连接,如果可以,则从modelscope下载模型,否则从 huggingface.co下载模型
音色获取
从 0.92 版本起,支持csv或pt格式的固定音色,下载后保存到软件目录下的 speaker 文件夹中即可
pt文件可从 https://github.com/6drf21e/ChatTTS_Speaker 项目提供的体验链接页面 (https://modelscope.cn/studios/ttwwwaa/ChatTTS_Speaker) 下载。
也可以从此页面 http://ttslist.aiqbh.com/10000cn/ 查看试听后将对应音色值填写到 “自定义音色值”文本框中
不同设备同一音色值seed,最终合成的声音会有差异的,以及同一设备相同音色值,音色也可能会有变化,尤其音调
常见问题与报错解决方法
修改http地址
默认地址是 http://127.0.0.1:9966,如果想修改,可打开目录下的 .env文件,将 WEB_ADDRESS=127.0.0.1:9966改为合适的ip和端口,比如修改为WEB_ADDRESS=192.168.0.10:9966以便局域网可访问
使用API请求 v0.5+
请求方法: POST
请求地址: http://127.0.0.1:9966/tts
请求参数:
text: str| 必须, 要合成语音的文字
voice: 可选,默认 2222, 决定音色的数字, 2222 | 7869 | 6653 | 4099 | 5099,可选其一,或者任意传入将随机使用音色
prompt: str| 可选,默认 空, 设定 笑声、停顿,例如 [oral_2][laugh_0][break_6]
temperature: float| 可选, 默认 0.3
top_p: float| 可选, 默认 0.7
top_k: int| 可选, 默认 20
skip_refine: int| 可选, 默认0, 1=跳过 refine text,0=不跳过
custom_voice: int| 可选, 默认0,自定义获取音色值时的种子值,需要大于0的整数,如果设置了则以此为准,将忽略 voice
返回:json数据
成功返回: {code:0,msg:ok,audio_files:[dict1,dict2]}
其中 audio_files 是字典数组,每个元素dict为 {filename:wav文件绝对路径,url:可下载的wav网址}
失败返回:
{code:1,msg:错误原因}
# API调用代码
import requests
res = requests.post(‘http://127.0.0.1:9966/tts’, data={
“text”: “若不懂无需填写”,
“prompt”: “”,
“voice”: “3333”,
“temperature”: 0.3,
“top_p”: 0.7,
“top_k”: 20,
“skip_refine”: 0,
“custom_voice”: 0
})
print(res.json())
#ok
{code:0, msg:’ok’, audio_files:[{filename: E:/python/chattts/static/wavs/20240601-22_12_12-c7456293f7b5e4dfd3ff83bbd884a23e.wav, url: http://127.0.0.1:9966/static/wavs/20240601-22_12_12-c7456293f7b5e4dfd3ff83bbd884a23e.wav}]}
#error
{code:1, msg:”error”}
在pyVideoTrans软件中使用
升级 pyVideoTrans 到 1.82+ https://github.com/jianchang512/pyvideotrans
点击菜单-设置-ChatTTS,填写请求地址,默认应该填写 http://127.0.0.1:9966
测试无问题后,在主界面中选择ChatTTS